GPUへのMapReduceの適用に関する調査¶
2011年09月11日 報告
概要¶
近年、GPUの性能は飛躍的に向上しており、グラフィック専用の処理装置としてではなく、 数値計算等の汎用向けの処理に利用する、GPGPUに関する研究が盛んに行われている。 GPUは内部に多くのコアを備えており、NVIDIA社のGeForce GTX 580では、 512個ものコアを保持している。 これらのコアすべてを効率よく利用することで、GPUの持っている高いパフォーマンスを 引き出すことが出来るが、GPUの高い並列性を利用するためにはGPU特有の処理を 実装する必要があり、GPUプログラミングになじみの無い利用者にとっては処理の記述が困難である。
そこで、GPUを大量のコアを持ったプロセッサだと考え、 これらに対してMapReduceを適用することを検討する。 親しみやすいMapReduceインターフェースにあてはめて処理を記述するだけで、 GPUの高い並列性を生かしたプログラムが実装可能となる。 加えてGPUに関して深い知識が無くても、用意に性能を引き出すことができるようになる。
MapReduceについて¶
MapReduce[1]は、巨大なデータを複数の計算機を使って並列分散処理させるフレームワークであり、 Googleが検索エンジンのインデックス作成等、巨大なデータを処理するために考案されたアルゴリズムである。 MapReduceでは、map関数とreduce関数を定義するだけで、 大規模データの並列処理が可能となるシンプルなアルゴリズムである。 また、計算機の台数に応じて性能が直線的にスケールするといった特徴を備えている。
MapReduceが得意、不得意とする分野を以下に示す。
- 得意な分野
- 大量データ(数百Mバイト以上)の処理
- バッチ処理
- 不得意な事
- 小さなデータの処理
- インタラクティブな処理
MapReduceは、データ処理の信頼性をハードウェアではなくソフトウェアで補うアルゴリズムである。従来の大量のデータを処理する方法としては、ハードウェアの性能を高める方法(スケールアップ)や、MPI, CORBA等を利用する方法が考えられる。
ハードウェア性能を上げる方法は、コストがかかるという問題がある。また、スケールアップよりもスケールアウト(安価なコンピュータを大量に利用)するほうが性能が高く,コストも抑えられるという調査報告がある。MPIやCORBAを利用する場合は、データの分散化に関しては自分で考えて実装する必要があり、プログラマ側の負担が大きいという問題点がある。
MapReduceが適用可能な分野に関する研究はまだ始まったばかりであるため、どのような分野に適用できるかは分かっていない。Chu[2]らは、マルチコアプロセッサ上にMapReduceを実装し、機械学習を行った。16プロセッサを利用すると,おおよそどの学習も1コアを使った学習より8倍から16倍まで性能が上げることができた。Lin[3]らは、MapReduceをグラフアルゴリズムに適応させた。ダイクストラ法のようなグラフアルゴリズムにはMapReduceは適用しにくいことを指摘し、幅優先探索等が適応可能であることを示した。
GPUでのMapReduceの実装¶
A Map Reduce Framework for Programming Graphics Processors[4]¶
Catanzaroら[4]は、CUDAを利用してGPU上でのMapReduceの実装を行った。Catanzaroらは、SVM(Support Vector Machine)にGPUを用いたMapReduceを適用した所、CPUのみで実装した処理よりも32倍から150倍スピードアップを達成することができた。彼らは、MapReduceにあてはめるだけで簡単にGPUを用いた並列処理が可能であったとし、MapReduceのモデルはGPU上での並列計算にも適しているとしている。
Catanzaroらの実装には各map関数は単一のKey/Valueペアしか出力ができないという制約が存在している。加えて、GPUプログラミングの仕組みを隠すようなフレームワーク作成を目的としておらず、性能を引き出すためにはGPUのメモリ階層に関する知識が必要であるとしている。MapReduceをGPUへ適用するのは、GPUプログラミングの複雑さを隠すためであり、Catanzaroらの実装はMapReduceの良さを十分に生かし切れていないフレームワークとなっている。
Mars: A MapReduce Framework on Graphics Processors[5]¶
Mars[5]は、CUDAを用いたGPUによるMapReduceの実装である。GPUでの複雑なプログラミングを行うことなく,親しみやすいMapReduceインターフェースを使ってプログラムが可能であるとしている。MarsではQuad Core CPU上でのMapReduce実装より最大16倍高速化できたとしている。
著者らの目指すシステムは以下の通りである。
- 簡単にプログラミングができること
- 高性能なこと
Marsでは,MAP_COUNT, MAP, REDUCE_COUNT,REDUCEの4つの関数をユーザが定義する。MAP_COUNT, REDUCE_COUNT関数では出力されるデータ量を定義する。これは、GPUではあらかじめ出力されるデータ量を指定しておかなければならない制約の為である。Marsでは、データのロックを行わなくても書き込みが衝突しないような仕組み[7]を採用している。
Marsでは、データ処理にCPU(Mars Scheduler)とGPUの両方を用いる(図1)。データ処理の流れは以下の通りである。
- 入力するKey/Valueのペアをメインメモリ上の配列に配置する (CPU)
- run-time設定のパラメータの初期化を行う (GPU)
- メインメモリ上の入力データ配列をGPU上のデバイスメモリへとコピーする (CPU)
- GPU上にてMapを開始し,中間Key/Valueペアを配列へと保存する (GPU)
- もしnoSortがF(False)ならば,中間データをソートする (GPU)
- もしnoReduceがFならば,GPU上にてReduceを行い,結果を出力する.そうでなければ,中間データを最終的な結果として出力する (GPU)
- 結果をGPUのデバイスメモリからメインメモリへコピーする (CPU)
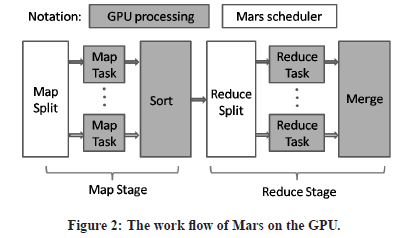
図1: Marsでの処理の流れ([5] Fig2より引用)
Marsでは、デバイスメモリより大きなデータを扱うことができないといった制約が存在する。またMap段階,Reduce段階の出力するデータ量をあらかじめ予測できない場合には、Marsを利用することができない。
DisMaRC: A Distributed Map Reduce framework on CUDA[6]¶
DisMaRCはCUDAとMPIを組み合わせたMapReduce実装(図2)である。
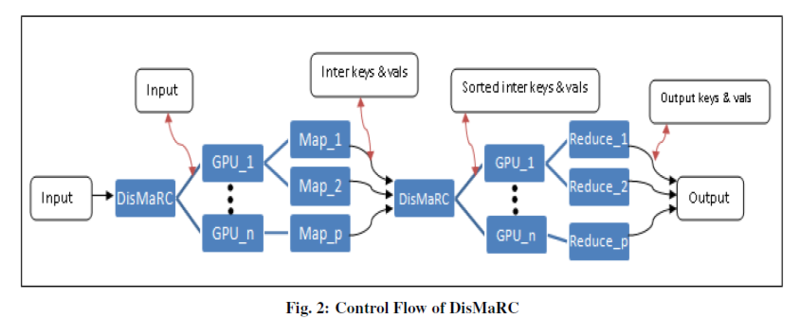
図2: Dismarkの処理の流れ([6] Fig2より引用)
Marsと同じく、MAP_COUNT, REDUCE_COUNT等が必要である。DisMaRCでは、Marsとの処理速度を比較しており、Marsよりも処理を高速化できたとしている。しかし、それほど速くなっているようには思えず、結果は微妙である。
Marsと同じく、Map段階、Reduce段階での出力するデータ量をあらかじめ予測できないような問題にはDisMaRCを利用することができない。加えてソートするデータを1つのマスターノードに集めるので、性能がスケールしない可能性が存在する。また、Fault Toreranceについては考えられていない。
まとめ¶
Catanzaroらの実装、Mars、及びDisMaRCの比較を下図に示す。
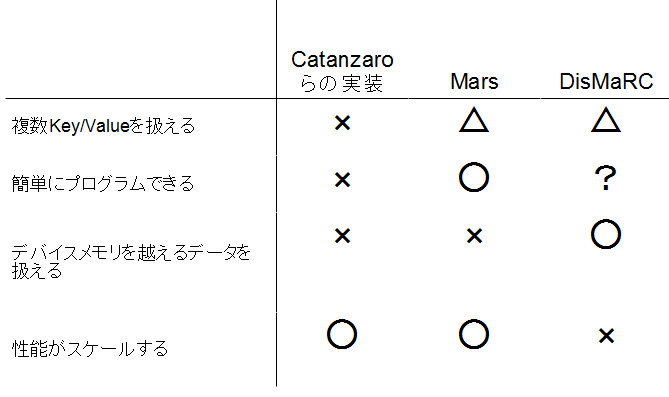
GPUへのMapReduceの適用について、親しみやすいMapReduceインターフェースにあてはめた処理を記述するだけで、高い処理性能を引き出すという点においては、まだまだ改良の余地があると考えられる。Marsに関しては、CUDAでの実装が著者らのWebサイト(http://www.cse.ust.hk/gpuqp/Mars.html)にて公開されているので、興味のある方はMarsの改良を試みてみるのも面白いかと思う。
参考文献¶
[1] Jeffrey Dean, Sanjay Ghemawat, ”MapReduce:Simplified Data Processing on Large Clusters”, OSDI 2004.
[2] Cheng-Tao Chu, Sang Kyun Kim, Yi-An Lin, YuanYuan Yu, Gary R. Bradski, Andrew Y. Ng, Kunle Olukotun. "Map-Reduce for Machine Learning on Multicore" In Proceedings of NIPS'2006. pp.281~288
[3] Jimmy Lin, Chris Dyer, "Data-Intensive Text Processing with MapReduce", http://www.umiacs.umd.edu/~jimmylin/book.html (2011-09-11 accessed)
[4] Bryan Catanzaro, Narayanan Sundaram and Kurt Keutzer "A Map Reduce Framework for Programming Graphics Processors", In Workshop on Software Tools for MultiCore Systems, 2008.
[5] Bingsheng He, Wenbin Fang, Qiong Luo, Naga K.Govindaraju, and Tuyong Wang "Mars: A MapReduce Framework on Graphics Processors", PACT 2008.
[6] Alok Mooley, Karthik Murthy, Harshdeep Singh, DisMaRC "A Distributed Map Reduce framework on CUDA", 2009.
[7] B. He, K. Yang, R. Fang, M. Lu, N. Govindaraju, Q. Luo, and P. Sander: "Relational joins on graphics processors". In SIGMOD, 2008.